Color Models:
A color model is an abstract mathematical model describing the way colors can be represented as tuples of numbers, typically as three or four values or color components. When this model is associated with a precise description of how the components are to be interpreted (viewing conditions, etc.), the resulting set of colors is called color space. This section describes ways in which human color vision can be modeled.
A color model is an orderly system for creating a whole range of colors from a small set of primary colors. There are two types of color models, those that are subtractive and those that are additive. Additive color models use light to display color while subtractive models use printing inks. Colors perceived in additive models are the result of transmitted light. Colors perceived in subtractive models are the result of reflected light.
The Two Most Common Color Models:
There are several established color models used in computer graphics, but the two most common are the RGB model (Red-Green-Blue) for computer display and the CMYK model (Cyan-Magenta-Yellow-Black) for printing.
1) RGB Color Model-*Additive color model
*For computer displays
*Uses light to display color
*Colors result from transmitted light
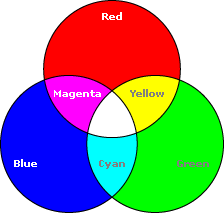
*Red+Green+Blue=White
2) CMYK Color Model-*Subtractive color model
*For printed material
*Uses ink to display color
*Colors result from reflected light
*Cyan+Magenta+Yellow=Black
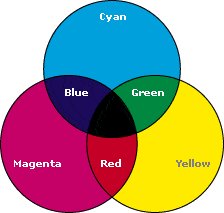
In the RGB model notice that the overlapping of additive colors (red, green and blue) results in subtractive colors (cyan, magenta and yellow). In the CMYK model notice that the overlapping of subtractive colors (cyan, magenta and yellow) results in additive colors (red, green and blue).
refer : http://www.sketchpad.net/basics4.htm
http://en.wikipedia.org/wiki/Color_model
http://en.wikipedia.org/wiki/RGB_color_model
A color model is an abstract mathematical model describing the way colors can be represented as tuples of numbers, typically as three or four values or color components. When this model is associated with a precise description of how the components are to be interpreted (viewing conditions, etc.), the resulting set of colors is called color space. This section describes ways in which human color vision can be modeled.
A color model is an orderly system for creating a whole range of colors from a small set of primary colors. There are two types of color models, those that are subtractive and those that are additive. Additive color models use light to display color while subtractive models use printing inks. Colors perceived in additive models are the result of transmitted light. Colors perceived in subtractive models are the result of reflected light.
The Two Most Common Color Models:
There are several established color models used in computer graphics, but the two most common are the RGB model (Red-Green-Blue) for computer display and the CMYK model (Cyan-Magenta-Yellow-Black) for printing.
1) RGB Color Model-*Additive color model
*For computer displays
*Uses light to display color
*Colors result from transmitted light
*Red+Green+Blue=White
2) CMYK Color Model-*Subtractive color model
*For printed material
*Uses ink to display color
*Colors result from reflected light
*Cyan+Magenta+Yellow=Black
In the RGB model notice that the overlapping of additive colors (red, green and blue) results in subtractive colors (cyan, magenta and yellow). In the CMYK model notice that the overlapping of subtractive colors (cyan, magenta and yellow) results in additive colors (red, green and blue).
refer : http://www.sketchpad.net/basics4.htm
http://en.wikipedia.org/wiki/Color_model
http://en.wikipedia.org/wiki/RGB_color_model